2. ОПИСАНИЕ НЕОПРЕДЕЛЕННОСТЕЙ В ТЕОРИИ ПРИНЯТИЯ РЕШЕНИЙ
2.3.4. Интервальные данные в задачах оценивания параметров (на примере гамма-распределения)
Рассмотрим классическую в прикладной математической статистике параметрическую задачу оценивания. Исходные данные – выборка x 1 , x 2 , ..., x n , состоящая из n действительных чисел. В вероятностной модели простой случайной выборки ее элементы x 1 , x 2 , ..., x n считаются набором реализаций n независимых одинаково распределенных случайных величин. Будем считать, что эти величины имеют плотность f ( x ). В параметрической статистической теории предполагается, что плотность f ( x ) известна с точностью до конечномерного параметра, т.е., при некотором Это, конечно, весьма сильное предположение, которое требует обоснования и проверки; однако в настоящее время параметрическая теория оценивания широко используется в различных прикладных областях.
Все результаты наблюдений определяются с некоторой точностью, в частности, записываются с помощью конечного числа значащих цифр (обычно 2 – 5). Следовательно, все реальные распределения результатов наблюдений дискретны. Обычно считают, что эти дискретные распределения достаточно хорошо приближаются непрерывными. Уточняя это утверждение, приходим к уже рассматривавшейся модели, согласно которой статистику доступны лишь величины
y j = x j + j , j = 1, 2, ... , n ,
где x i – «истинные» значения, погрешности наблюдений (включая погрешности дискретизации). В вероятностной модели принимаем, что n пар
образуют простую случайную выборку из некоторого двумерного распределения, причем x 1 , x 2 , ..., x n - выборка из распределения с плотностью . Необходимо учитывать, что и - реализации зависимых случайных величин (если считать их независимыми, то распределение yi будет непрерывным, а не дискретным). Поскольку систематическую ошибку, как правило, нельзя полностью исключить , то необходимо рассматривать случай Нет оснований априори принимать и нормальность распределения погрешностей (согласно сводкам экспериментальных данных о разнообразии форм распределения погрешностей измерений, приведенным в и , в подавляющем большинстве случаев гипотеза о нормальном распределении погрешностей оказалась неприемлемой для средств измерений различных типов). Таким образом, все три распространенных представления о свойствах погрешностей не адекватны реальности. Влияние погрешностей наблюдений на свойства статистических моделей необходимо изучать на основе иных моделей, а именно, моделей интервальной статистики.
Пусть - характеристика величины погрешности, например, средняя квадратическая ошибка . В классической математической статистике считается пренебрежимо малой () при фиксированном объеме выборки n . Общие результаты доказываются в асимптотике . Таким образом, в классической математической статистике сначала делается предельный переход , а затем предельный переход . В статистике интервальных данных принимаем, что объем выборки достаточно велик (), но всем измерениям соответствует одна и та же характеристика погрешности . Полезные для анализа реальных данных предельные теоремы получаем при . В статистике интервальных данных сначала делается предельный переход , а затем предельный переход . Итак, в обеих теориях используются одни и те же два предельных перехода: и , но в разном порядке. Утверждения обеих теорий принципиально различны.
Изложение ниже идет на примере оценивания параметров гамма-распределения, хотя аналогичные результаты можно получить и для других параметрических семейств, а также для задач проверки гипотез (см. ниже) и т.д. Наша цель – продемонстрировать основные черты подхода статистики интервальных данных. Его разработка была стимулирована подготовкой ГОСТ 11.011-83 .
Отметим, что постановки статистики объектов нечисловой природы соответствуют подходу, принятому в общей теории устойчивости . В соответствии с этим подходом выборке x = (x 1 , x 2 , ..., x n ) ставится в соответствие множество допустимых отклонений G (x ), т.е. множество возможных значений вектора результатов наблюдений y = (y 1 , y 2 , ..., y n ). Если известно, что абсолютная погрешность результатов измерений не превосходит , то множество допустимых отклонений имеет вид
Если известно, что относительная погрешность не превосходит , то множество допустимых отклонений имеет вид
![]()
Теория устойчивости позволяет учесть «наихудшие» отклонения, т.е. приводит к выводам типа минимаксных, в то время как конкретные модели погрешностей позволяют делать заключения о поведении статистик «в среднем».
Оценки параметров гамма-распределения. Как известно, случайная величина Х имеет гамма-распределение, если ее плотность такова :

где a – параметр формы, b – параметр масштаба, - гамма-функция. Отметим, что есть и иные способы параметризации семейства гамма-распределений .
Поскольку M (X ) = ab , D (X ) = ab 2 , то оценки метода имеют вид
![]()
где - выборочное среднее арифметическое, а s 2 – выборочная дисперсия. Можно показать, что при больших n
с точностью до бесконечно малых более высокого порядка.
Оценка максимального правдоподобия a * имеет вид :
![]() (12)
(12)
где - функция, обратная к функции

При больших n
Как и для оценок метода моментов, оценка максимального правдоподобия b * параметра масштаба имеет вид
При больших n с точностью до бесконечно малых более высокого порядка
![]()
Используя свойства гамма-функции, можно показать , что при больших а
с точностью до бесконечно малых более высокого порядка. Сравнивая с формулами (11), убеждаемся в том, что средние квадраты ошибок для оценок метода моментов больше соответствующих средних квадратов ошибок для оценок максимального правдоподобия. Таким образом, с точки зрения классической математической статистики оценки максимального правдоподобия имеют преимущество по сравнению с оценками метода моментов.
Необходимость учета погрешностей измерений. Положим

Из свойств функции следует , что при малых v
В силу состоятельности оценки максимального правдоподобия a * из формулы (13) следует, что по вероятности при
Согласно модели статистики интервальных данных результатами наблюдений являются не x i , а y i , вместо v по реальным данным рассчитывают

 (14)
(14)
В силу закона больших чисел при достаточно малой погрешности , обеспечивающей возможность приближения для слагаемых в формуле (14), или, что эквивалентно, при достаточно малых предельной абсолютной погрешности в формуле (1) или достаточно малой предельной относительной погрешности имеем при

по вероятности (в предположении, что все погрешности одинаково распределены). Таким образом, наличие погрешностей вносит сдвиг, вообще говоря, не исчезающий при росте объема выборки. Следовательно, если то оценка максимального правдоподобия не является состоятельной. Имеем
![]()
где величина a *(y ) определена по формуле (12) с заменой x i на y i , i =1,2,…,n . Из формулы (13) следует , что
т.е. влияние погрешностей измерений увеличивается по мере роста а .
Из формул для v и w следует, что с точностью до бесконечно малых более высокого порядка
 (16)
(16)
С целью нахождения асимптотического распределения w выделим, используя формулу (16) и формулу для v , главные члены в соответствующих слагаемых
Таким образом, величина w представлена в виде суммы независимых одинаково распределенных случайных величин (с точностью до зависящего от случая остаточного члена порядка 1/n ). В каждом слагаемом выделяются две части – одна, соответствующая Мб и вторая, в которую входят На основе представления (17) можно показать, что при распределения случайных величин v и w асимптотически нормальны, причем
Из асимптотического совпадения дисперсий v и w , вида параметров асимптотического распределения (при ) оценки максимального правдоподобия a * и формулы (15) вытекает одно из основных соотношений статистики интервальных данных
![]() (18)
(18)
Соотношение (18) уточняет утверждение о несостоятельности a *. Из него следует также, что не имеет смысла безгранично увеличивать объем выборки n с целью повышения точности оценивания параметра а , поскольку при этом уменьшается только второе слагаемое в (18), а первое остается постоянным.
В соответствии с общим подходом статистики интервальных данных в стандарте предлагается определять рациональный объем выборки n rat определять из условия «уравнивания погрешностей» (предложено в монографии ) различных видов в формуле (18), т.е. из условия
![]()
Упрощая это уравнение в предположении получаем, что
Согласно сказанному выше, целесообразно использовать лишь выборки с объемами . Превышение рационального объема выборки не дает существенного повышения точности оценивания.
Применение методов теории устойчивости. Найдем асимптотическую нотну. Как следует из вида главного линейного члена в формуле (17), решение оптимизационной задачи
![]()
соответствующей ограничениям на абсолютные погрешности, имеет вид

Однако при этом пары не образуют простую случайную выборку, т.к. в выражения для входит . Однако при можно заменить на М(х 1). Тогда получаем, что
при a >1, где

Таким образом, с точностью до бесконечно малых более высокого порядка нотна имеет вид
![]()
Применим полученные результаты к построению доверительных интервалов. В постановке классической математической статистики (т.е. при ) доверительный интервал для параметра формы а , соответствующий доверительной вероятности , имеет вид
где - квантиль порядка стандартного нормального распределения с математическим ожиданием 0 и дисперсией 1,
В постановке статистики интервальных данных (т.е. при ) следует рассматривать доверительный интервал

в вероятностной постановке (пары образуют простую случайную выборку) и в оптимизационной постановке. Как в вероятностной, так и в оптимизационной постановках длина доверительного интервала не стремится к 0 при
Если ограничения наложены на предельную относительную погрешность, задана величина , то значение с можно найти с помощью следующих правил приближенных вычислений .
(I) Относительная погрешность суммы заключена между наибольшей и наименьшей из относительных погрешностей слагаемых.
(II) Относительная погрешность произведения и частного равна сумме относительных погрешностей сомножителей или, соответственно, делимого и делителя.
Можно показать, что в рамках статистики интервальных данных с ограничениями на относительную погрешность правила (I) и (II) являются строгими утверждениями при
Обозначим относительную погрешность некоторой величины t через ОП(t ), абсолютную погрешность – через АП(t ).
Из правила (I) следует, что ОП() = , а из правила (II) – что
Поскольку рассмотрения ведутся при то в силу неравенства Чебышева
по вероятности при поскольку и числитель,
и знаменатель в (19) с близкой к 1 вероятностью лежат в промежутке ![]() где константа d может быть определена с помощью упомянутого
неравенства Чебышева.
где константа d может быть определена с помощью упомянутого
неравенства Чебышева.
Поскольку при справедливости (19) с точностью до бесконечно малых более высокого порядка

то с помощью трех последних соотношений имеем
 (20)
(20)
Применим еще одно правило приближенных вычислений .
(III) Предельная абсолютная погрешность суммы равна сумме предельных абсолютных погрешностей слагаемых.
Из (20) и правила (III) следует, что
Из (15) и (21) вытекает , что
![]()
откуда в соответствии с ранее полученной формулой для рационального объема выборки с заменой получаем, что
В частности, при a = 5,00, = 0,01 получаем т.е. в ситуации, в которой были получены данные о наработке резцов до предельного состояния , проводить более 50 наблюдений нерационально.
В соответствии с ранее проведенными рассмотрениями асимптотический доверительный интервал для a , соответствующий доверительной вероятности = 0,95, имеет вид
В частности, при ![]() имеем асимптотический
доверительный интервал вместо при
имеем асимптотический
доверительный интервал вместо при
При больших а в силу соображений, приведенных при выводе формулы (19), можно связать между собой относительную и абсолютную погрешности результатов наблюдений x i :
![]() (21)
(21)
Следовательно, при больших а имеем
![]()
Таким образом, проведенные рассуждения дали возможность вычислить асимптотику интеграла, задающего величину А .
Сравнение методов оценивания. Изучим влияние погрешностей измерений (с ограничениями на абсолютную погрешность) на оценку метода моментов. Имеем
Погрешность s 2 зависит от способа вычисления s 2 . Если используется формула
 (22)
(22)
то необходимо использовать соотношения
По сравнению с анализом влияния погрешностей на оценку а* здесь возникает новый момент – необходимость учета погрешностей в случайной составляющей отклонения оценки от оцениваемого параметра, в то время как при рассмотрении оценки максимального правдоподобия погрешности давали лишь смещение. Примем в соответствии с неравенством Чебышева
![]() (23)
(23)
Если вычислять s 2 по формуле
 (24)
(24)
то аналогичные вычисления дают, что
![]()
т.е. погрешность при больших а существенно больше. Хотя правые части формул (22) и (24) тождественно равны, но погрешности вычислений по этим формулам весьма отличаются. Связано это с тем, что в формуле (24) последняя операция – нахождение разности двух больших чисел, примерно равных по величине (для выборки из гамма-распределения при большом значении параметра формы).
Из полученных результатов следует, что

При выводе этой формулы использована линеаризация влияния погрешностей (выделение главного линейного члена). Используя связь (21) между абсолютной и относительной погрешностями, можно записать
![]()
Эта формула отличается от приведенной в
а
![]()
б) для повышения точности оценивания объем выборки целесообразно безгранично увеличивать;
в) оценки максимального правдоподобия лучше оценок метода моментов,
то в статистике интервальных данных, учитывающей погрешности измерений, соответственно:
а) не существует состоятельных оценок: для любой оценки a n существует константа с такая, что
![]()
б) не имеет смысла рассматривать объемы выборок, большие «рационального объема выборки»
в) оценки метода моментов в обширной области параметров лучше оценок максимального правдоподобия, в частности, при и при
Ясно, что приведенные выше результаты справедливы не только для рассмотренной задачи оценивания параметров гамма-распределения, но и для многих других постановок прикладной математической статистики.
Метрологические, методические, статистические и вычислительные погрешности. Целесообразно выделить ряд видов погрешностей статистических данных. Погрешности, вызванные неточностью измерения исходных данных, называем метрологическими. Их максимальное значение можно оценить с помощью нотны. Впрочем, выше на примере оценивания параметров гамма-распределения показано, что переход от максимального отклонения к реально имеющемуся в вероятностно-статистической модели не меняет выводы (с точностью до умножения предельных значений погрешностей или на константы). Как правило, метрологические погрешности не убывают с ростом объема выборки.
Методические погрешности вызваны неадекватностью вероятностно-статистической модели, отклонением реальности от ее предпосылок. Неадекватность обычно не исчезает при росте объема выборки. Методические погрешности целесообразно изучать с помощью «общей схемы устойчивости» , обобщающей популярную в теории робастных статистических процедур модель засорения большими выбросами. В настоящей главе методические погрешности не рассматриваются.
Статистическая погрешность – это та погрешность, которая традиционно рассматривается в математической статистике. Ее характеристики – дисперсия оценки, дополнение до 1 мощности критерия при фиксированной альтернативе и т.д. Как правило, статистическая погрешность стремится к 0 при росте объема выборки.
Вычислительная погрешность определяется алгоритмами расчета, в частности, правилами округления. На уровне чистой математики справедливо тождество правых частей формул (22) и (24), задающих выборочную дисперсию s 2 , а на уровне вычислительной математики формула (22) дает при определенных условиях существенно больше верных значащих цифр, чем вторая .
Выше на примере задачи оценивания параметров гамма-распределения рассмотрено совместное действие метрологических и вычислительных погрешностей, причем погрешности вычислений оценивались по классическим правилам для ручного счета . Оказалось, что при таком подходе оценки метода моментов имеют преимущество перед оценками максимального правдоподобия в обширной области изменения параметров. Однако, если учитывать только метрологические погрешности, как это делалось выше в примерах 1-5, то с помощью аналогичных выкладок можно показать, что оценки этих двух типов имеют (при достаточно больших n ) одинаковую погрешность.
Вычислительную погрешность здесь подробно не рассматриваем. Ряд интересных результатов о ее роли в статистике получили Н.Н.Ляшенко и М.С.Никулин .
| Предыдущая |
Рассмотрим Гамма распределение, вычислим его математическое ожидание, дисперсию, моду. С помощью функции MS EXCEL ГАММА.РАСП() построим графики функции распределения и плотности вероятности. Сгенерируем массив случайных чисел и произведем оценку параметров распределения.
Гамма распределение
(англ. Gamma
distribution
)
зависит от 2-х параметров: r
(определяет форму распределения) и λ (определяет масштаб). этого распределения задается следующей формулой:
где Г(r) – гамма-функция:
если r – положительное целое, то Г(r)=(r-1)!
Вышеуказанная форма записи плотности распределения
наглядно показывает его связь с . При r=1 Гамма распределение
сводится к Экспоненциальному распределению
с параметром λ.
Если параметр λ – целое число, то Гамма распределение является суммой r независимых и одинаково распределенных по экспоненциальному закону с параметром λ случайных величин x . Таким образом, случайная величина y = x 1 + x 2 +… x r имеет гамма распределение с параметрами r и λ.
, в свою очередь, тесно связано с дискретным . Если Распределение Пуассона описывает число случайных событий, произошедших за определенный интервал времени, то Экспоненциальное распределение, в этом случае,описывает длину временного интервала между двумя последовательными событиями.
Из этого следует, что, например, если время до наступления первого события описывается экспоненциальным распределением с параметром λ, то время до наступления второго события описывается гамма распределением с r = 2 и тем же параметром λ.
Гамма распределение в MS EXCEL
В MS EXCEL принята эквивалентная, но отличающаяся параметрами форма записи плотности гамма распределения .

Параметр α (альфа ) эквивалентен параметру r , а параметр b (бета ) – параметру 1/λ . Ниже будем придерживаться именно такой записи, т.к. это облегчит написание формул.
В MS EXCEL, начиная с версии 2010, для Гамма распределения имеется функция ГАММА.РАСП() , английское название - GAMMA.DIST(), которая позволяет вычислить плотность вероятности (см. формулу выше) и (вероятность, что случайная величина X, имеющая гамма распределение , примет значение меньше или равное x).
Примечание : До MS EXCEL 2010 в EXCEL была функция ГАММАРАСП() , которая позволяет вычислить интегральную функцию распределения и плотность вероятности . ГАММАРАСП() оставлена в MS EXCEL 2010 для совместимости.
Графики функций
В файле примера приведены графики плотности распределения вероятности и интегральной функции распределения .


Гамма распределение имеет обозначение Gamma(альфа; бета).
Примечание : Для удобства написания формул в файле примера для параметров распределения альфа и бета созданы соответствующие .
Примечание : Зависимость от 2-х параметров позволяет построить распределения разнообразных форм, что расширяет применение этого распределения. Гамма распределение , как и Экспоненциальное распределение часто используется для расчета времени ожидания между случайными событиями. Кроме того, возможно использование применение этого распределения для моделирования уровня осадков и при проектировании дорог.
Как было показано выше, если параметр альфа = 1, то функция ГАММА.РАСП() возвращает с параметром 1/бета . Если параметр бета = 1, функция ГАММА.РАСП() возвращает стандартное гамма распределение .
Примечание : Т.к. является частным случаем гамма распределения , то формула =ГАММА.РАСП(x;n/2;2;ИСТИНА ) для целого положительного n возвращает тот же результат, что и формула =ХИ2.РАСП(x;n; ИСТИНА) или =1-ХИ2.РАСП.ПХ(x;n) . А формула =ГАММА.РАСП(x;n/2;2;ЛОЖЬ) возвращает тот же результат, что и формула =ХИ2.РАСП(x;n; ЛОЖЬ) , т.е. плотность вероятности ХИ2-распределения.
В файле примера на листе Графики приведен расчет гамма распределения равного альфа*бета и
ОСНОВНЫЕ ЗАКОНЫ РАСПРЕДЕЛЕНИЯ НЕПРЕРЫВНЫХ СЛУЧАЙНЫХ ВЕЛИЧИН
Н ормальный закон распределения и его значение в теории вероятностей. Логарифмически нормальный закон. Гамма-распределение. Экспоненциальный закон и его использование в теории надежности, теории очередей. Равномерный закон. Распределение . Распределение Стьюдента. Распределение Фишера.
1. Нормальный закон распределения (закон Гаусса).
Плотность вероятности нормально распределенной случайной величины выражается формулой:
 . (8.1)
. (8.1)
На рис. 16 представлена кривая распределения. Она симметрична относительно
Рис. 16 Рис. 17
точки (точка максимума). При уменьшении ордината точки максимума неограниченно возрастает. При этом кривая пропорционально сплющивается вдоль оси абсцисс, так что площадь ее под графиком остается равной единице (рис. 17).
Нормальный закон распределения очень широко распространен в задачах практики. Объяснить причины широкого распространения нормального закона распределения впервые удалось Ляпунову. Он показал, что если случайная величина может рассматриваться как сумма большого числа малых слагаемых, то при достаточно общих условиях закон распределения этой случайной величины близок к нормальному независимо от того, каковы законы распределения отдельных слагаемых. А так как практически случайные величины в большинстве случаев бывают результатом действия большого числа различных причин, то нормальный закон оказывается наиболее распространенным законом распределения (подробнее об этом см. главу 9). Укажем числовые характеристики нормально распределенной случайной величины:
Таким образом, параметры и в выражении (8.1) нормального закона распределения представляют собою математическое ожидание и среднее квадратическое отклонение случайной величины. Принимая это во внимание, формулу (8.1) можно переписать следующим образом:
 .
.
Эта формула показывает, что нормальный закон распределения полностью определяется математическим ожиданием и дисперсией случайной величины. Таким образом, математическое ожидание и дисперсия полностью характеризуют нормально распределенную случайную величину. Само собой разумеется, что в общем случае, когда характер закона распределения неизвестен, знания математического ожидания и дисперсии недостаточно для определения этого закона распределения.
Пример 1 . Вычислить вероятность того, что нормально распределенная случайная величина удовлетворяет неравенству .
Решение. Пользуясь свойством 3 плотности вероятности (глава 4, п. 4), получаем:
 .
.
 ,
,
где - функция Лапласа (см. приложение 2).
Проделаем некоторые числовые расчеты. Если положить , в условиях примера 1, то
Последний результат
означает, что с вероятностью, близкой
к единице (),
случайная величина, подчиняющаяся
нормальному закону распределения, не
выходит за пределы интервала
![]() .
Это утверждение носит название правила
трех сигм
.
.
Это утверждение носит название правила
трех сигм
.
Наконец, если
,
,
то случайная величина, распределенная
по нормальному закону с такими параметрами,
называется стандартизованной нормальной
величиной. На рис. 18 изображен график
плотности вероятности этой величины
 .
.
2. Логарифмически нормальное распределение.
Говорят, что случайная величина имеет логарифмически нормальное распределение (сокращенно логнормальное распределение ), если ее логарифм распределен нормально, т. е. если
где величина имеет нормальное распределение с параметрами , .
Плотность логнормального распределения задается следующей формулой:
 ,
.
,
.
Математическое ожидание и дисперсию определяют по формулам
 ,
,
 .
.
Кривая распределения приведена на рис. 19.
Логарифмически нормальное распределение встречается в ряде технических задач. Оно дает распределение размеров частиц при дроблении, распределение содержаний элементов и минералов в изверженных горных породах, распределение численности рыб в море и т.д. Оно встречается во всех
тех задачах, где логарифм рассматриваемой величины можно представить в виде суммы большого числа независимых равномерно малых величин:
 ,
,
т. е.
 ,
где
независимы.
,
где
независимы.
Рассмотрим плотность

параметры распределения. Распределение с такой плотностью называется гамма распределение . Приведем график плотности этого распределения при


Величина

рассматриваемая как функция переменной

называется гамма-функцией и имеет следующие, легко доказываемые свойства

Это распределение обозначается

Гамма распределение обобщает экспоненциальное распределение и превращается в него при

Гамма распределение с целым параметром

называется
распределение Эрланга
порядка  и обозначается
и обозначается

Распределение

где n – целое, называется распределение хи-квадрат и обозначается

Построение меры в конечномерном пространстве Борелевская сигма-алгебра в конечномерном пространстве
Борелевская сигма-алгебра на пространстве действительных векторов определяется аналогично борелевской сигма-алгебре на прямой с заменой прямоугольников

на параллелепипеды

Обозначим ее

Эта сигма-алгебра содержит все практически важные множества векторов. Множество, принадлежащее борелевской сигма-алгебре называется борелевское множество .
Определение случайного вектора

основное вероятностное пространство

пространство векторов с борелевской сигма-алгеброй

Вероятностная мера, определенная на борелевской сигма-алгебре по формуле
называется распределением случайного вектора.

случайный вектор и

называется функция распределения (иначе - совместная функция распределения) случайного вектора

Аналогично одномерному случаю определяются дискретные и непрерывные случайные вектора и их распределения.
Плотность распределения случайного вектора f(x) – это функция, удовлетворяющая условию

Мера Лебега в конечномерном пространстве
Мера Лебега в конечномерном пространстве это мера, приписывающая параллелепипеду его объем. В частности, мера Лебега прямоугольника это его площадь.
Мера Лебега на квадрате - Задача о встрече
Рассмотрим следующую задачу.
Два человека договорились встретиться в определенном месте в течение часа и ждать друг друга не более 10 минут. Найти вероятность, того они встретятся, если момент прихода каждого совершенно случаен.
Для решения задачи построим следующую вероятностную модель. Исходом опыта является вектор

где первая координата – момент прихода первого человека, вторая – момент прихода второго. Сигма-алгебра – все борелевские подмножества единичного (1 час=1 единица времени) квадрата. Предположение о совершенной случайности моментов прихода приводит к вероятностной мере, которая приписывает каждому множеству единичного квадрата его площадь. Эта мера называется мера Лебега на квадрате . Подсчитаем вероятность интересующего нас события. Два человека встретятся, если

Площадь этой наклонной полосы


Независимые случайные величины
Случайные величины
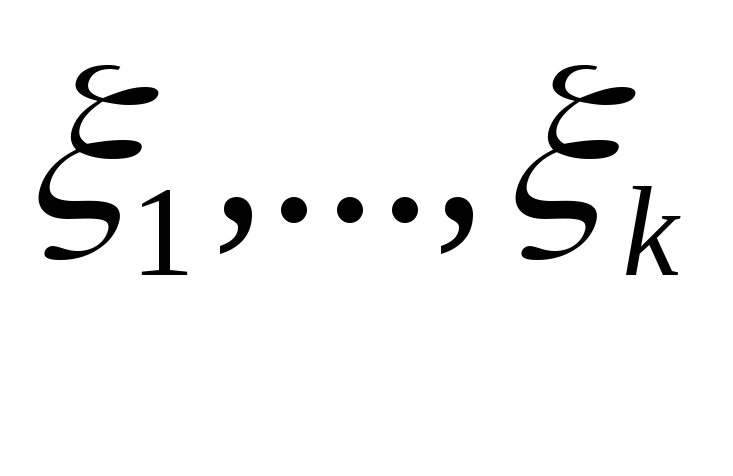 ,
,
заданные на одном вероятностном пространстве, называются независимыми, если для любых борелевских множеств

Простейший вид гамма-распределения - это распределение с плотностью
где
![]() -
параметр сдвига,
- гамма-функция, т.е.
-
параметр сдвига,
- гамма-функция, т.е.
 (2)
(2)
Каждое
распределение можно "развернуть"
в масштабно-сдвиговое семейство.
Действительно, для случайной величины
,
имеющей функцию распределения,
рассмотрим семейство случайных величин![]() ,
где- параметр масштаба, а-
параметр сдвига. Тогда функция
распределенияесть
,
где- параметр масштаба, а-
параметр сдвига. Тогда функция
распределенияесть .
.
Включая каждое распределение с плотностью вида (1) в масштабно-сдвиговое семейство, получаем принятую в параметризацию семейства гамма-распределений:

Здесь
![]() - параметр формы,- параметр масштаба,- параметр сдвига, гамма-функциязадается формулой (2).
- параметр формы,- параметр масштаба,- параметр сдвига, гамма-функциязадается формулой (2).
В
литературе имеются и иные параметризации.
Так, вместо параметра
часто используют параметр![]() .
Иногда рассматривают двухпараметрическое
семейство, опуская параметр сдвига, но
сохраняя параметр масштаба или его
аналог - параметр
.
Иногда рассматривают двухпараметрическое
семейство, опуская параметр сдвига, но
сохраняя параметр масштаба или его
аналог - параметр![]() .
Для некоторых прикладных задач (например,
при изучении надежности технических
устройств) это оправдано, поскольку из
содержательных соображений представляется
естественным принять, что плотность
распределения вероятностей положительна
для положительных значений аргумента
и только для них. С этим предположением
связана многолетняя дискуссия в 80-х
годах о "назначаемых показателях
надежности", на которой не будем
останавливаться.
.
Для некоторых прикладных задач (например,
при изучении надежности технических
устройств) это оправдано, поскольку из
содержательных соображений представляется
естественным принять, что плотность
распределения вероятностей положительна
для положительных значений аргумента
и только для них. С этим предположением
связана многолетняя дискуссия в 80-х
годах о "назначаемых показателях
надежности", на которой не будем
останавливаться.
Частные
случаи гамма-распределения при
определенных значениях параметров
имеют специальные названия. При
имеем экспоненциальное распределение.
При натуральномигамма-распределение - это распределение
Эрланга, используемое, в частности, в
теории массового обслуживания. Если
случайная величинаимеет гамма-распределение с параметром
формытаким, что![]() - целое число,и, тоимеет распределение хи-квадратсстепенями свободы.
- целое число,и, тоимеет распределение хи-квадратсстепенями свободы.
Области применения гамма-распределения
Гамма-распределение имеет широкие приложения в различных областях технических наук (в частности, в надежности и теории испытаний), в метеорологии, медицине, экономике . В частности, гамма-распределению могут быть подчинены общий срок службы изделия, длина цепочки токопроводящих пылинок, время достижения изделием предельного состояния при коррозии, время наработки до k-го отказа и т.д. . Продолжительность жизни больных хроническими заболеваниями, время достижения определенного эффекта при лечении в ряде случаев имеют гамма-распределение. Это распределение оказалось наиболее адекватным для описания спроса в ряде экономико-математических моделей управления запасами .
Возможность
применения гамма-распределения в ряде
прикладных задач иногда может быть
обоснована свойством вопроизводимости:
сумма
независимых экспоненциально распределенных
случайных величин с одним и тем же
параметромимеет гамма-распределение с параметрами
формы,
масштаба![]() и сдвига.
Поэтому гамма-распределение часто
используют в тех прикладных областях,
в которых применяют экспоненциальное
распределение.
и сдвига.
Поэтому гамма-распределение часто
используют в тех прикладных областях,
в которых применяют экспоненциальное
распределение.
Различным вопросам статистической теории, связанным с гамма-распределением, посвящены сотни публикаций (см. сводки ). В данной статье, не претендующей на всеохватность, рассматриваются лишь некоторые математико-статистические задачи, связанные с разработкой государственного стандарта .